

Vai trò của dữ liệu thì chúng ta không cần bàn luận nữa. Hôm nay mình sẻ chia sẻ một vài phương pháp và khó khăn khi cào dữ liệu (crawl data) từ những phương pháp, công cụ mình đã ứng dụng và một số vấn đề gặp phải trong quá trình làm luận văn. (có 2 khái niệm là data crawling và data scraping nhưng mình chỉ nói nôn na là thu thập dữ liệu, các bạn có thể đọc thêm để phân biệt)
Cào ở dữ liệu ở đây mình đề cập là xây dựng một tool để đi thu thập dữ liệu ở một số website mà chúng ta cần, đơn thuần cũng chỉ là gởi một request HTTP/HTTPS trực tiếp hoặc dùng một browser driver truy cập đến trang đích để lấy nội dung trang về rồi tiến hành parse nội dung để lấy dữ liệu. Hầu hết các trang web đều không thể ngăn cấm việc bot ghé thăm vì trong đó có bot của các search engine như google, bing,… tuy nhiên họ cũng không thể nào cho phép truy cập thỏa mái vì điều này làm giảm hiệu năng hoặc thậm chí sập cả server. Chính vì vậy đa số các website đều quy định và tìm cách hạn chế, ngăn chặn việc crawler quá mức, thậm chí có cả bẫy (traps) để chặn crawler khiến cho việc thu thập dữ liệu của chúng ta cũng gặp không ít khó khăn.
Trước hết mình sẽ giới thiệu qua một số tool/lib/framework phổ biến để thực hiện thu thập dữ liệu, mặc dù việc cào dữ liệu chỉ đơn thuần là gởi request để lấy nội dung nhưng bạn cũng nên dùng thư viện sẵn có để thu thập (trừ khi các bạn muốn phát triển 1 thư viện mới) thay vì tự gởi request bằng thư viện HTTP trong các ngôn ngữ sẵn có vì các bạn sẽ phải handle rất nhiều thứ từ đa luồng, kiểm soát request, parsing,… rất tốn thời gian để viết lại. Sử dụng các thư viện sẵn có thì bạn cũng không cần lo về khả năng mở rộng, tùy biến của mình, các thư viện đa số đã thiết kế theo kiến trúc mở cung cấp các middlewares, pipelines cho người dùng tùy biến.
| Scrapy | Selenium | Cheerio | Puppeteer | |
|---|---|---|---|---|
| Advantages | - Bất đồng bộ chính là thứ giúp cho scrapy có hiệu năng tuyệt vời. Sử dụng rất ít RAM, CPU. Tài liệu đầy đủ, plugins rất nhiều. Thiết kế theo một kiến trúc khá tốt, dev có thể dễ dàng tùy chỉnh middlewares, pipelines và thêm các function tùy ý. | - Dễ tiếp cận cho beginer. Có thể lấy được nội dung trang render bằng javascript. Có thể thao tác như một người dùng | - Hỗ trợ parse DOM giống như jquery. Bất đồng bộ, khá nhanh | - Giống như selenium, puppeteer cũng sử dụng browser driver để lấy nội dung trang nên có thể lấy được nội dung các trang render bằng js và thao tác như một người dùng. |
| Disadvantages | - Hơi phức tạp cho beginer. Quá dư thừa chức năng nếu chỉ dùng cho 1 project nhỏ và đơn giản. Không thể lấy nội dung trang được render bằng js, tuy nhiên chúng ta có thể kết hợp với Splash. | - Tiêu tốn nhiều tài nguyên vì nó cần đến một browser driver (tưởng tượng như bạn mở 1 tab chrome thì sẽ tốn bao nhiêu RAM, CPU). Rất chậm, nên selenium không phù hợp với một project cào dữ liệu lớn. | - Chỉ đơn thuần là trình phân tích (parser). Không thể lấy nội dung trang được render bằng js | - Tiêu tốn RAM, CPU. Chậm |
Hầu hết các ngôn ngữ lập trình đều có những thư viện hỗ trợ thu thập dữ liệu, tuy nhiên Python sẽ là ngôn ngữ mà mình gợi ý các bạn nên chọn cho dự án thu thập dữ liệu của mình, Scrapy là một framework trong python hỗ trợ thu thập dữ liệu cực mạnh, hơn nữa python có hỗ trợ khá nhiều thư viện để xử lý dữ liệu.
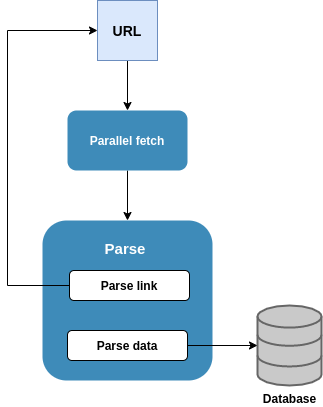
Nhập môn thu thập dữ liệu, kiến trúc chung của một crawler sẽ gồm 3 phần: queue chứa URL, downloader, parser. Luồng hoạt động sẽ diễn ra như sau:
- Cung cấp một URL để start (hoặc một list URL)
- Downloader tiến hành tải xuống nội dung trang
- Parser rút trích dữ liệu (store nếu cần) và đồng thời rút trích ra URL kế tiếp và thêm vào queue URL
- Quá trình sẽ lặp lại cho đến hết URL trong queue
Để làm quen với việc thu thập dữ liệu, mình khuyên các bạn nên làm qua 10 bài thực hành trên trang Scrapingclub (Learn Web Scraping Using Python For Free) theo bất kỳ thư viện hỗ trợ thu thập dữ liệu nào bạn muốn, solutions thì mình cũng đã làm từ lúc mình học cơ bản https://github.com/lhsang/Spiders (sử dụng scrapy) các bạn có thể tham khảo.
Về vấn đề thu thập thông tin để tránh vi phạm các tiêu chuẩn, quy định thì các bạn nên phân tích file http://domain.com/robots.txt trước khi cào, file robots.txt sẽ định quy cho biết Crawler của bạn được truy cập những trang nào, không được truy cập trang nào và thời gian delay mỗi request. Ngoài ra user-agent là một header bạn có thể tùy ý, tuy nhiên về vấn đề đạo đức nghề nghiệp các bạn không nên fake giá trị này.
Phần tiếp theo mình sẽ nói về một số khó khăn đã gặp và giải pháp trong quá trình thu thập dữ liệu phục vụ cho luận văn tốt nghiệp:
- Các trang hạn chế số lượng truy cập trong một khoảng thời gian: để tránh việc một IP làm quá tải server, các trang thường phải giới hạn số request của một IP trong một phút (thường sẽ họ sẽ cho biết thời gian deplay mỗi request trong file robots.txt), có một số lượng lớn trang cần thu thập thì môi phút vài request thì quá ít cho nhu cầu của mình và thậm chí nếu gửi nhiều hơn quy định, crawler còn có thể bị ban trong vài phút. Giải pháp là mình đã sử dụng thêm proxy server, giá proxy cũng không quá mắc (tầm $0.4 IP/tháng, khuyên các bạn không nên mua của các nhà cung cấp từ Việt Nam - người từng trải), mỗi request mình sẽ đổi IP liên tục thì sẽ tránh được ban IP. Nếu không cần thiết phải đổi IP thì ban có thể tăng thời gian DELAY_REQUEST để cách biệt các request, giảm CONCURRENT_REQUESTS (số request đồng thời) và có thể cheat nhẹ user-agent bất chấp đạo đức :))
- Nội dung trang render bằng Javascript: vì nhu cầu mình crawl nhiều nên mình chọn Scrapy, tuy nhiên scrapy lại không hỗ trợ lấy dữ liệu ở các trang render bằng js (Ajax, React,…) để biết rằng trang này có render bằng js ra nội dung không, bạn chỉ cần Ctrl+U rồi xem có nội dung html như hiển thị không, hay chỉ là một thẻ body rồi js chèn vào sau. Như đã đề cập scrapy có thể sử dụng kèm với headless browser như Splash để chờ trang web render ra nội dung và cookie, việc này làm tốn thêm một ít thời gian chờ nhưng vẫn nhanh hơn các lựa chọn khác scrapy.
- Cấu trúc trang thay đổi: đôi lúc sites thay đôỉ cấu trúc (HTML tags thay đổi), chúng ta phải xác định đúng thẻ thì mới lấy được dữ liệu. Nên cài đặt cho crawler cơ chế phát hiện cấu trúc thay đổi và thông báo để chúng ta biết và chỉnh sửa hoặc áp dụng cấu trúc mới để parse đúng dữ liệu.
- Required đủ cookie, headers: đa số các trang đều yêu cầu một số headers và cookie là phải có trong request, chúng ta có thể dùng Chrome DevTools để xem các header và cookie này, tuy nhiên ở nhiều trang headers, cookie này không được set ngay từ đầu mà trong quá trình request sẽ gởi request đến một URL khác để lấy thông tin headers, cookie hoặc ngay địa chỉ URL của bạn nhưng lần đầu là để lấy headers, cookie lần sau mới lấy nội dung (trường hợp này, nếu không có đủ headers server sẽ buộc crawler request vô hạn). Giải pháp là chúng ta phải biết quan sát mà lấy headers, cookie phù hợp để gắn vào request thôi =))
- Bất đồng bộ và multithread vẫn chưa đủ: mỗi ngày mình phải gởi hơn vài chục triệu request, scrapy hỗ trợ bất đồng bộ, tuy nhiên một process chưa đủ đáp ứng nhu cầu lớn như vậy trong một ngày, giải pháp là tăng số process lên (có thể cho chạy ở nhiều server), liên quan đến vấn đề xử lý song song các bạn phải tính toán để chia URL ra cho các process hợp lý nhất.
- Lưu trữ dữ liệu: tùy nhu cầu bạn sẽ chọn hệ quản trị cơ sở dữ liệu phù hợp, với project của mình vì nhu cầu lưu trữ lớn (hơn 11 triệu record mỗi ngày đổ vào database) và cần tốc độ truy vẫn nhanh thì mình chọn mongodb. MongoDB thuộc loại NoSQL lưu trữ theo dạng document (BSON), schema linh hoạt, không phải join, kết hợp với đánh indexes thì tốc độ khá là nhanh (dữ liệu 1 tỷ records mình có thể truy vấn dưới 1s) hơn nữa mongodb còn thiết kế để đáp ứng nhu cầu phân tán nên có thể sharding hay replication để mở rộng, tăng hiệu năng và đảm bảo tính available cho hệ thống. Vấn đề lưu xuống liên tục cũng có thể quá tải database, bạn có thể cache tạm một nơi rồi insert_many thay vì insert_one.
Trên là những chia sẻ mà mình rút trích được từ những vấn đề gặp phải trong quá trình làm luận văn mà mình gặp phải, ngoài ra vẫn còn kha khá issues mà mình chưa gặp phải nữa nếu biết các bạn có thể chia sẻ thêm dưới phần bình luận để cùng tranh luận, cảm ơn các bạn.