

Giới thiệu về Full-Text Search
Có lẽ chúng ta đều biết và sử dụng qua một kỹ thuật tìm kiếm rất cơ bản, đó là thông qua câu lệnh LIKE của SQL.
SELECT column_name(s)
FROM table_name
WHERE column_name LIKE pattern;
Sử dụng LIKE, chúng ta chỉ tìm kiếm ở column đã định trước, do đó không gian tìm kiếm bị giới hạn hơn. Về tốc độ, câu lệnh LIKE cũng tương đương với lệnh chúng ta matching pattern cho từng chuỗi của từng rows của column tương ứng thì bạn cũng hiểu tốc độ sẽ như thế nào rồi. Kết quả tìm kiếm có độ nhiễu cao và gặp vấn đề về từ đồng nghĩa.
Một giải pháp tìm kiếm đầy đủ, nhanh hơn và linh hoạt hơn đó là Full-text search. Full-text search (FTS) là một kỹ thuật tìm kiếm kết quả trên cơ sở dữ liệu chứa “toàn bộ” các kí tự (text) của một hoặc một số tài liệu, bài báo,…(document), hoặc là của website.
Full-text search trong PostgreSQL
PostgreSQL (thời điểm viết bài latest released version là 12.2) có các toán tử ~, ~*, LIKE, ILIKE để tìm kiếm cho kiểu dữ liệu văn bản, tuy nhiên như đề cập ở trên thì các phương pháp này chó ra kết quả không như mong đợi và thời gian query lâu.
FTS trong postgreql xuất phát từ ý tưởng tiền xử lý (preprocess) document ở thời điểm index để tiết kiệm thời gian cho sau này query (cho quá trình tìm kiếm). Tiền xử lý sẽ bao gồm:
- Parsing document to lexemes: rất hữu ích để phân biệt các loại lexemes (từ vựng) vì các loại lexemes khác nhau có thể được xử lý khác nhau, ví dụ: chữ số, chữ, từ phức, địa chỉ email,…
- Apply các quy tắc ngôn ngữ để chuẩn hóa lexeme thành dạng nguyên mẫu, ví dụ: see, saw, seen đều đưa về dạng nguyên mẫu là see để lưu trữ. Stopword - những từ phổ biến, xuất hiện hầu hết trong mỗi document, tuy nhiên không thể phân biệt được gì từ chúng, nên postgresql cũng có các bộ từ điển và tự động loại bỏ stopword trước khi lưu.
SELECT to_tsvector('english','in the list of stop words'); -- english: dùng bộ từ điển tiếng anh (default english)
----------------------------
'list':3 'stop':5 'word':6
- Store document đã tiền xử lý theo một cách tối ưu để tìm kiếm nhanh hơn. Ví dụ biểu diễn tài liệu dưới dạng một mảng các từ vựng được sắp xếp. Lưu trữ vị ví xuất hiện, tần suất xuất hiện nhằm để xếp hạng (Ranking).
PostgreSQL là một cơ sở dữ liệu có thể mở rộng, nên nó có thêm datatype mới là tsvector dùng cho tiền xử lý và lưu tài liệu, tsquery dùng để query. Và thêm operator @@ được defined cho datatype này. Và đương nhiên FTS cũng có thể được tăng tốc khi đánh index.
Text search functions
1. Parsing documents: tsvector
to_tsvector([ config regconfig, ] document text)
tsvector là một kiểu dữ liệu dạng document được dùng để tối ưu hóa full text search. chuỗi được phân tách và sắp xếp lại theo thứ tự từ điển, các từ trùng lặp chỉ lưu trữ một lần, đồng thời hàm có sử dụng dictionary (english - default) để loại bỏ những từ ngữ không quan trọng (mạo từ, tobe, …) và chuyển về dạng nguyên mẫu để lưu trữ tiện cho việc tìm kiếm. Kèm theo đó là vị trí xuất hiện trong câu.
SELECT to_tsvector('english', 'A task was canceled.');
-----------------------
'cancel':4 'task':2
Ví dụ trên chúng ta thấy câu được tác thành các từ riêng biệt, được sắp xếp theo thứ tự từ điển, kèm theo đó là vị trí xuất hiện trong câu và các dấu câu, stopword bị lọai bỏ (theo từ điển tiếng anh).
2. Parsing queries: tsquery
to_tsquery([ config regconfig, ] querytext text)
tsquery là một kiểu dữ liệu cho các truy vấn văn bản với sự hỗ trợ của toán tử boolean: & (and), | (or). Tsquery bao gồm các lexemes(từ vựng) và các toán tử boolean ở giữa.
SELECT plainto_tsquery('english', 'The Fat Rats');
-----------------
'fat' & 'rat'
SELECT to_tsquery('english', 'The & Fat & Rats');
---------------
'fat' & 'rat'
SELECT to_tsquery('english', 'The & Fat | Rats');
---------------
'fat' | 'rat'
3. Một số hàm khác.
| Function | Return Type | Description | Example | Result |
|---|---|---|---|---|
| array_to_tsvector(text[]) | tsvector | convert mảng lexemes thành tsvector | array_to_tsvector(’{fat,cat,rat}’::text[]) | ‘cat’ ‘fat’ ‘rat’ |
| plainto_tsquery([ config regconfig , ] query text) | tsquery | hàm tsquery bỏ qua dấu câu | plainto_tsquery(’english’, ‘The Fat Rats’) | ‘fat’ & ‘rat’ |
| setweight(vector tsvector, weight “char”) | tsvector | assign weight cho các phần tử trong vector | setweight(‘fat:2,4 cat:3 rat:5B’::tsvector, ‘A’) | ‘cat’:3A ‘fat’:2A,4A ‘rat’:5A |
| get_current_ts_config() | regconfig | get config măc định | get_current_ts_config() | english |
| ts_rank([ weights float4[], ] vector tsvector, query tsquery [, normalization integer ]) | float4 | tính điểm ranking | ts_rank(textsearch, query) | 0.818 |
| … |
Mình chỉ đề cập vài hàm hay dùng, để tìm hiểu nhiều hơn mời các bạn đọc tiếp tại trang chủ postgres
FTS operator
- Full text search trong postgresql sử dụng toán tử @@ cho 2 loại dữ liệu tsvector và tsquery. FTS operator còn hỗ trợ các kiểu dữ liệu như text và varchar cho phép setup full-text search đơn giản (nhưng không hỗ trợ ranking).
tsvector @@ tsquery
tsquery @@ tsvector
text|varchar @@ text|tsquery
Toán tử @@ return TRUE nếu tsvector chứa tsquery.
SELECT to_tsvector('a fat cat sat on a mat - it ate a fat rats') @@ to_tsquery('The & Fat & Rats');
-------
t
SELECT to_tsvector('a fat cat sat on a mat - it ate a fat rats') @@ to_tsquery('The & Fat & Dogs');
--------
f
SELECT 'a fat cat sat on a mat - it ate a fat rats' @@ to_tsquery('The & Fat & rat');
-------
t
SELECT 'a fat cat sat on a mat - it ate a fat rats' @@ 'The & Fat & rat';
-------
t
- Toán tử || để nối 2 vector.
SELECT to_tsvector('xin chao') || to_tsvector('hello world')
---------------
'chao':2 'hello':3 'world':4 'xin':1
- Các toán tử khác (Nguồn: Text Search Functions and Operators)
| Operator | Return Type | Description | Example | Result |
|---|---|---|---|---|
| @@ | boolean | tsvector matches tsquery ? | to_tsvector(‘fat cats ate rats’) @@ to_tsquery(‘cat & rat’) | t |
| @@@ | boolean | deprecated synonym for @@ | to_tsvector(‘fat cats ate rats’) @@@ to_tsquery(‘cat & rat’) | t |
| || | tsvector | concatenate tsvectors | ‘a:1 b:2’::tsvector || ‘c:1 d:2 b:3’::tsvector | ‘a’:1 ‘b’:2,5 ‘c’:3 ’d’:4 |
| && | tsquery | AND tsquerys together | ‘fat | rat’::tsquery && ‘cat’::tsquery | ( ‘fat’ | ‘rat’ ) & ‘cat’ |
| || | tsquery | OR tsquerys together | ‘fat | rat’::tsquery || ‘cat’::tsquery | ( ‘fat’ | ‘rat’ ) | ‘cat’ |
| !! | tsquery | negate a tsquery | !! ‘cat’::tsquery | !‘cat’ |
| <-> | tsquery | tsquery followed by tsquery | to_tsquery(‘fat’) <-> to_tsquery(‘rat’) | ‘fat’ <-> ‘rat’ |
| @> | boolean | tsquery contains another ? | ‘cat’::tsquery @> ‘cat & rat’::tsquery | f |
| <@ | boolean | tsquery is contained in ? | ‘cat’::tsquery <@ ‘cat & rat’::tsquery | t |
Ranking search results
Ranking nhằm mục đích đo lường mức độ phù hợp của document đối với một query cụ thể. Postgres cung cấp 2 hàm ranking:
- Ranking dựa trên tần số của các từ được match
ts_rank([ weights float4[], ] vector tsvector, query tsquery [, normalization integer ]) returns float4
- Cũng tương tự như ts_rank tuy nhiên hàm còn tính theo mật độ bao phủ của input trong document
ts_rank_cd([ weights float4[], ] vector tsvector, query tsquery [, normalization integer ]) returns float4
Ví dụ:
SELECT ts_rank( to_tsvector('name lastname name lastname'), to_tsquery('name & lastname'));
---
ts_rank: 0,3400053*
SELECT ts_rank_cd( to_tsvector('name lastname name lastname'), to_tsquery('name & lastname'));
---
ts_rank_cd: 0,3
SELECT ts_rank_cd( to_tsvector('name lastname abc xyz name lastname'), to_tsquery('name & lastname'));
---
ts_rank_cd: 0,233*
- Cả 2 hàm trên đều, tham số weights là optional, các nhãn
{D-weight, C-weight, B-weight, A-weight}
nếu không chỉ định tham số weights thì trọng số mặc định là:
{0.1, 0.2, 0.4, 1.0}
Indexes
Có 2 loại index có thể dùng để tăng tốc full-text search trong postgres là: GIN và GIST
-
Gin (Generalized Inverted Indexes) Loại index này sẽ hữu ích khi một chỉ mục phải ánh xạ tới nhiều giá trị trong cùng một bản ghi, trong khi đó B-Tree lại chỉ được tối ưu hóa nếu như một bản ghi chỉ có một giá trị khóa duy nhất. Chỉ mục GIN cũng rất hữu ích trong việc đánh chỉ mục các giá trị là mảng, hoặc khi phải thực hiện các truy vấn là full-text search.
-
GiST - Generalized Search Tree: Loại index này cho phép bạn xây dựng cấu trúc cây cân bằng chung, và có thể được sử dụng cho nhiều loại so sánh ngoài hai loại so sánh bằng và so sánh phạm vi. Chỉ mục này cũng được sử dụng để đánh chỉ mục cho các kiểu dữ liệu hình học, cũng như thực hiện full-text search.
Vậy chọn GIN hay GiST để dùng?
- GIN tốn thời gian đánh index lâu hơn tuy nhiên lại tìm kiếm nhanh hơn GiST (3 lần)
- GIN update cũng lâu hơn (vừa phải) so với GiST, tuy nhiên sẽ lâu hơn tầm 10 lần nếu vô hiệu hóa fast-update.
- Chi phí về không gian của GIN cũng lớn hơn 2-3 lần so với GiST
Bạn có thể bỏ qua phần phân tích sau nếu thấy bài đã đủ dài và đủ rối :))
Phân tích một chút về BTree và GIN index:
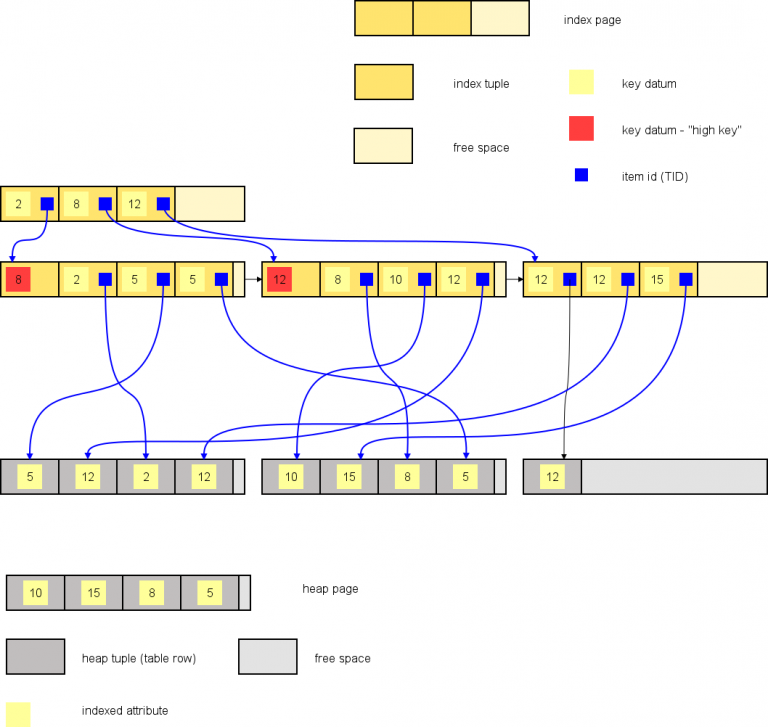
Trên là B-Tree index (thực ra BTree cũng có 2 loại là B-Tree và B+Tree nhưng ở đây mình giả sử B-Tree có trúc như vậy). Index bao gồm các trang, mỗi trang bao gồm nhiều index tuple và free space. Index tuple là cấu trúc bao gồm:
- key datum: gía trị của cột được đánh index (column). Trên một trang lá (leaf page), key datum chính là con trỏ tham chiếu đến heap tuple (table row). Còn các page ở trong thì datatum là con trỏ chỉ đến các cây con được tham chiếu.
- tuple identifier (TID) - hay còn gọi là item pointer: thông tin về địa chỉ vật lý (địa chỉ trên disk) của index tuple hoặc heap tuple được tham chiếu (mỗi row chỉ tham chiếu chính xác bởi một TID)
Mỗi row của table (table đánh index) đều phải được insert một tuple index vào cây, ngay cả khi một row khác có cùng giá trị khóa (key) đã tồn tại trên đó. Việc insert như vậy sẽ gây ra sự phân tách trang (số lượng entry trong 1 page đầy), ảnh hưởng đến trang khác và chiều cao của cây.
GIN index
Cấu trúc các trang trong (internal pages) của GIN và B-tree không có gì khác biệt. Điều làm khác biệt giữa chúng là các trang lá (leaf pages). Tùy thuộc vào số lượng entries có cùng key thì GIN sẽ có cơ chế:
- Posting list: nếu số lượng row có cùng key còn ít, thì leaf page là một trang chứa posting list.
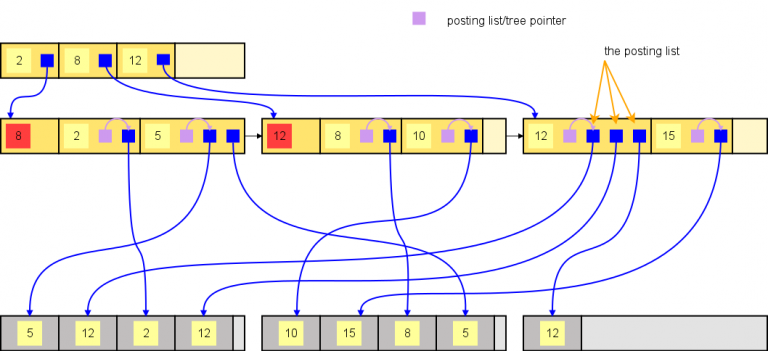
Key bây giờ là duy nhất trên leaf page. Index tuple sẽ không trỏ trực tiếp đến các rows tương ứng mà sẽ trỏ đến một posting list là danh sách chứa các con trỏ (TIDs) cho tất cả các row có chứa giá trị tương ứng. Khi insert một row mới mà đã có key entry trên cây thì nó chỉ cần tìm đến entry và thêm TID của row mới vào posting list, làm như vậy sẽ không chia trang trên cây nữa. Chú ý rằng các items trong posting list sẽ được sắp xếp tăng dần theo TID.
- Posting tree:
Tuy đã lưu dạng entry tuple, nhưng khi có quá nhiều row cùng giá trị (entry tuple nhiều trong 1 trang) thì cây riêng lại được tạo ra để chứa các TIDs - cây này gọi là posting tree.
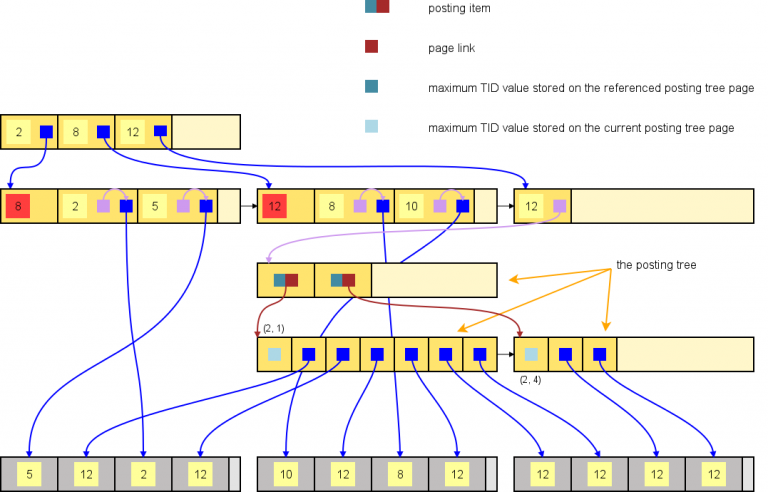
Posting tree cũng là một cấu trúc B-Tree riêng biệt được lưu trữ trên các trang của GIN index, trong trường hợp này TID của row sẽ được dùng làm key (TID vẫn được sắp xếp như trên posting list).
Có nhiều posting tree trong một GIN index, mỗi cây đại diện cho một giá trị (key) cụ thể. Và một row trong table có thể được tham chiếu bởi nhiều TID được lưu ở các posting list/tree khác nhau.
Áp dụng vào một dự án thực tế sẽ như thế nào?
- Cách mình thường hay dùng FTS này là mình sẽ tạo một column để chứa giá trị tsvector (đánh trọng số nếu cần) và đánh index trên nó. Sau đó tạo trigger để cập nhật field khi INSERT và UPDATE. Sau đó mọi thứ mình chỉ cần query trên column này một cách nhanh chóng.
PostgreSQL’s full text search so với một số giải pháp khác
Tùy vào nhu cầu tìm kiếm, resources mà chúng ta có những lựa chọn như Elastic, Algolia hay full text search của postgresql. Tuy nhiên với mình, những project có quy mô vừa và nhỏ thì mình thường dùng Full text search trong postgresql hơn vì:
- Không cần đến phần mềm hay thư viện nào khác.
- Không cần thêm server riêng cho module tìm kiếm.
- Dùng chính database sử dụng cho application để query tìm kiếm. Nên sẽ dễ kiểm soát và không cần quan tâm đến vấn đề đồng bộ so với giải pháp như Elastic.